
L’Evoluzione Finale dei Modelli 231:
il Modello Predittivo di Rischi 231 AI-Driven
Di Stefano Barlini, MBA, Certified AI Officer, CIA, CISA, ISO 31000 Professional&Trainer, CCSA, QAR con oltre 20 anni di esperienza nell’implementazione e aggiornamento dei Modelli 231 a favore di società quotate e non quotate di diversissima complessità e business, trainer e facilitatore esperto, nonché autore di un consistente numero di pubblicazioni sui programmi di conformità ai requisiti di cui al Decreto Legislativo 231/2001.
Esperto di dominio IA&GRC per Compet-e Srl, leader nel settore delle soluzioni digitali per la compliance con oltre 25 anni e centinaia di clienti soddisfatti che cercano insieme tecnologia e competenze specialistiche negli ambiti della Privacy GDPR, Sicurezza delle Informazioni, NIS2/DORA, DLgs 231/2001, AML, Whistleblowing, etc. Punto di riferimento per la RegTech nell’Ecosistema di Tesisquare®, Compet-e è rivenditore esclusivo per l’Italia della piattaforma Diligent®, la prima e unica soluzione a livello globale disegnata per gestire in maniera centralizzata tutti processi GRC (Governance, Risk Management, Compliance).
Quest’opera è stata rilasciata con licenza Creative Commons Attribuzione – Non Commerciale 4.0 Internazionale. Per leggere una copia della licenza visita il sito web https://creativecommons.org/licenses/by-nc/4.0/
Premessa e Ringraziamenti
In un contesto normativo sempre più complesso e dinamico, le organizzazioni che adottano un Modello 231 sanno quanto sia cruciale una valutazione dei rischi-reato accurata, aggiornata e ben supportata. Oggi, grazie all’Artificial Intelligence (AI), questo processo può essere rivoluzionato, migliorando la precisione, l’efficacia e la capacità di adattarsi su base continua a nuovi rischi emergenti derivanti dal continuo evolversi delle circostanze interne ed esterne. In questo articolo condivido le spiegazioni e riflessioni da me illustrate, in occasione di un recente webinar organizzato da Compet-e, per spiegare e dimostrare come l“AI can do it better” anche in ambito GRC, inclusi ovviamente i programmi di compliance al D.Lgs. 231/2001.
Ringrazio il Prof. Hernan Huwyler, MBA CPA per avermi fortemente ispirato su questo tema: la redazione del presente contributo in cui descrivo il Modello Predittivo di Rischi 231 AI-driven è chiaramente una conseguenza delle interazioni con Hernan.
Ringrazio Compet-e srl per avermi dato l’opportunità di presentare queste riflessioni in un webinar da loro organizzato il 20/3/2025 dal titolo “Come l’Intelligenza Artificiale può potenziare in maniera incredibile la valutazione dei rischi-reato alla base del tuo Modello 231 🤖” di cui sono stato relatore.
Chi è il relatore

Sono Stefano Barlini e per Compet-e agisco come esperto di dominio in ambito GRC e Internal Audit.
Come potete notare dai titoli sono un professionista specializzato proprio nel dominio GRC, avendo conseguito nel tempo alcune delle più importanti certificazioni professionali del settore. Ultimamente anche una specifica certificazione in ambito AI Governance & Risk Management che se volete mi dà titolo oggi per miscelare due argomenti apparentemente lontani, ma in realtà molto vicini: AI e 231.
Mi occupo di Modelli 231 fin dagli inizi del Decreto 231 e ho curato un consistente numero di progetti 231 per società molto diverse tra loro (quotate e non).
Ho fatto parte e faccio parte di Organismi di Vigilanza (nel complesso una ventina) dove ho potuto ovviamente sperimentare concretamente cosa c’è dopo una implementazione o un aggiornamento di un Modello 231 (dopo che il consulente consegna i suoi deliverables).
In quasi 25 anni di esperienza in Italia e all’estero, ho avuto la fortuna di lavorare con un buon numero di professionisti che oggi ricoprono importanti ruoli in ambito IA&GRC presso prestigiose aziende. Questo è per me motivo di grande orgoglio.
Ho iniziato in una Big 4 (Deloitte) nella practice del RC e poi proseguito in questi anni come consulente in una second-tier prima di approdare in Compet-e.
Chi è Compet-e
Compet-e è insieme Soluzioni Digitali e Consulenza Specialistica. Di fronte ai requisiti normativi sempre più stringenti per le aziende che rendono la gestione manuale sempre più costosa, inefficiente ed alto rischio errore, Compet-e si differenzia da tutti gli altri competitors offrendo da 25 anni soluzioni RegTech di altissimo livello: soluzioni in cui lo strumento/la tecnologia si fonde con le competenze specialistiche di dominio cioè relative alla normativa specifica tipicamente di livello nazionale che riguarda orizzontalmente la generalità delle imprese o un’ampia parte.
Un track record da leader nel settore dei software in ambito compliance (25 anni, centinaia di clienti soddisfatti, riferimento per la RegTech nell’Ecosistema di Tesisquare) fanno di Compet-e un player solido e unico nel panorama nazionale e da poco anche agganciato al network internazionale con il player e leader globale Diligent nel settore GRC.
Gli ambiti o domini funzionali sono il GDPR (storico), NIS2/Sicurezza informazioni e reti, il Whistleblowing e ovviamente il Decreto Legislativo 231/2001, oltre a quelli ulteriori che trovate illustrati nella slide.
Artificial Intelligence – Concetti Base | Cosa è l’AI
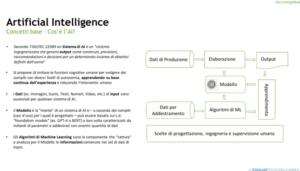
Dobbiamo partire dai concetti base dell’AI e quindi per chi già mastica qualcosa sarà un ripasso, mentre per i neofiti sarà un accenno importante per comprendere meglio come l’AI può aiutare nei programmi di conformità (tra cui quelli 231) e in generale nella gestione dei rischi.
Troviamo anzitutto un disegno illustrativo di un sistema di AI. Possiamo notare che si tratta di un sistema vero e proprio già solo dalla numerosità delle componenti. Un ulteriore elemento che può subito cogliersi è la presenza di una fase di addestramento (prima del rilascio in produzione intendo) e una fase di messa in produzione vera e propria con uno schema pur sempre input-elaborazione-out sebbene con approccio completamente nuovo rispetto ad un normale software (privo di AI intendo).
Come possiamo definire un sistema AI? Quando ci sono tante definizioni anche molto diverse tra loro, io suggerisco sempre di partire dalle definizioni ISO perché a loro volta sono la sintesi/incontro di tante correnti di pensiero. Ed è quello che facciamo subito.
Secondo l’ISO/IEC 22989 un Sistema di AI è un “sistema ingegnerizzato che genera output come contenuti, previsioni, raccomandazioni o decisioni per un determinato insieme di obiettivi definiti dall’uomo”
Quindi alla base di un sistema di AI c’è l’essere umano con le sue scelte di progettazione, ingegneria e naturalmente supervisione e l’output è rappresentato da «contenuti, previsioni, raccomandazioni o decisioni». Teniamolo a mente perché ci sarà utile.
Si chiama AI perché si propone di imitare l’intelligenza umana con sempre maggiore autonomia (cioè con progressivo minore intervento dell’uomo) e per far ciò (alla stregua di un essere umano) apprendendo continuamente dall’esperienza (si adattano), sulla base dei dati e delle informazioni con cui entra in contatto
L’apprendimento continuo sulla base dell’esperienza è quello che già distingue un sistema AI da un «normale» software: quest’ultimo è un insieme di SE___ALLORA che ripete gli stessi task secondo quanto codificato e sostanzialmente (in assenza di modifiche nel codice) eseguendoli sempre nello stesso modo, per cui usando lo stesso input otterremo sempre lo stesso output (ieri, oggi e domani, sempre). Questo non vale invece per un sistema di AI che impara dai dati e cambia la propria performance nel tempo.
L’AI impara quindi dai dati senza essere programmata esplicitamente, cambiando e migliorando la propria performance nel tempo (come l’essere umano che apprende e migliora con l’esperienza nel fare qualcosa). Questo significa che gli algoritmi (con miliardi di parametri) apprendono le informazioni direttamente dai dati, senza cioè equazioni predeterminate, modificando le proprie prestazioni in modo “automatico e adattivo” mano a mano che entrano in contatto con i dati da apprendere.
Abbiamo già ripetuto la parola dati un buon numero di volte: “Data is the new oil” a significare l’importanza che assume chi detiene i dati nel sistema economico guidato dall’AI! A loro volta – i dati possono essere reali (es. le immagini catturate dal sistema di videosorveglianza del Comune di Milano in una piazza centrale) o sintetici (creati in laboratorio).
Comunque potete vedere che la principale distinzione è tra dati per addestramento e dati di produzione quando il sistema di AI è appunto messo in produzione. E qui parliamo di quantità incredibilmente vaste ed ampie di dati, di cui l’AI ha continuo bisogno.
Se ci chiedessero di definire l’AI con una sola parola, dovremmo rispondere con «l’AI è … un Modello»! E qui ovviamente non c’entra niente il Modello 231! Pura coincidenza di sostantivi, anzi falso amico.
Il Modello è la “mente” di un sistema di AI e a seconda dei suoi compiti (casi d’uso) può poggiare su altri modelli a loro volta configurati con miliardi parametri e addestrati con enormi quantità di dati. Nel mettere a punto un nuovo sistema AI per uno specifico caso d’uso non si dovrà quindi ripartire da zero.
Una curiosità, se volete (iniziare a) capire come funziona un programma o uno strumento basato sull’AI, chiedete o cercate direttamente il Model Card del sistema/programma/strumento. E’ sostanzialmente l’etichetta o scheda di prodotto che contiene le informazioni principali e naturalmente descrive i possibili rischi. Intendo qui i rischi derivanti dall’uso dell’AI. Ce ne sono davvero tanti [alcuni sono ripetuti in maniera un po’ ossessiva dai media], ma comunque non sono oggetto di questo webinar ovviamente! Per noi oggi l’AI è uno strumento che può aiutarci incredibilmente nei compliance program!
Ma ora concentriamoci su una componente un po’ «oscura» (non se ne parla molto nel mainstream sull’AI) ma che è in realtà fondamentale per il funzionamento di qualsiasi sistema di AI: si tratta degli Algoritmi di Machine Learning. Teniamo bene a mente dove si collocano e quale è la loro funzione: catturare le informazioni contenute nei dati che sono dati in pasto all’AI.
Ad esempio analizzare e catturare il significato di una immagine di un uomo con una pistola in mano e/o l’immagine di un uomo con un disegno di una pistola sulla maglietta che indossa. Il dato è sempre l’immagine di un uomo, ma il significato è del tutto diverso!

Quindi gli algoritmi di machine learning apprendono le informazioni direttamente dai dati (catturano le info) – senza usare equazioni predeterminate (come invece fanno i software normali) – e incrementano le proprie le proprie prestazioni (cioè la qualità dei propri output ossia previsioni, raccomandazioni, contenuti o decisioni) in modo “automatico e adattivo” mano a mano che entrano in contatto con nuovi dati.
Come riescono a fare tutto questo?
Ci riescono grazie ai Modelli Probabilistici come la Regressione Logistica, gli Alberi Decisionali, la Rete Bayesiana, le Reti Neurali etc. che vi ho riepilogato in questa slide con una infografica molto efficace! Dateci pure un occhio per qualche secondo.
E cosa identificano questi Algoritmi di Machine Learning attraverso questi Modelli probabilistici? Identificano:
- I Pattern, ossia gli schemi ripetitivi come sono gli acquisti di cellulari accompagnati dall’acquisto contestuale di una cover
- I Trend, ossia il movimento nel tempo dei dati come un incremento delle vendite in un determinato periodo dell’anno o nei week end
- Le Correlazioni (“no causation”), ossia le relazioni tra dati come potrebbe essere l’acquisto di occhiali da sole e di gelati in estate
- Le Anomalie, ossia gli eventi rari/inusuali (ovviamente rispetto a quelli a più alta frequenza) come un improvviso addebito sulla carta di credito da un’area geografica del tutto nuova
Questa è la base di qualsiasi sistema di AI, incluso ad esempio il più famoso ChatGpt a cui chiedete di generare un testo e che – sulla base della qualità delle info di contesto che gli fornite – fa un buono o cattivo lavoro; oppure Netflix quando vi suggerisce o raccomanda un nuovo film; oppure i social media con un nuovo video o nuovo contenuto.
Possiamo allora dire senza timore di sbagliare molto che l’AI è nella sua essenza CALCOLO DELLE PROBABILITA’ (cit. Prof. Hernan Huwyler, MBA CPA).
Artificial Intelligence – Concetti Base | GenAI vs. PredAI
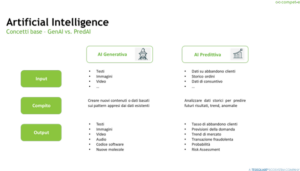
Facciamo quindi una panoramica dell’AI più nota e diffusa a cominciare da quella generativa (la più famosa e «consapevolmente» usata al mondo).
C’è un compito «Creare nuovi contenuti o dati basati sui pattern appresi dai dati esistenti», degli input «testi, immagini, video» e degli output «nuovi testi, nuove immagini, nuovi video, nuovi audio, nuovo codice software, nuove molecole nella ricerca farmaceutica, etc.)
Esiste però un’altra tipologia di AI meno nota e conosciuta dai più, ma che – oltre ad essere alla base di quella generativa – è già essa stessa in tanti sistemi, software, strumenti che usiamo tutti i giorni: è l’AI predittiva.
Qui il compito (caso d’uso) è analizzare dei dati storici per predire i futuri risultati, trend e anomalie sulla base appunto di input come dati storici come ad esempio i dati di abbandono dei clienti, lo storico degli ordini, i dati di consuntivo, etc.
L’output è appunto una previsione di quello che sarà il tasso di abbandono dei clienti, la domanda di un prodotto o servizio, il trend di mercato, una transazione fraudolenta (anomalia)… ma anche la probabilità di un evento o ancora di più la combinazione tra le conseguenze e la probabilità di un evento, cioè il RISK ASSESSMENT!
Dall’AI alla 231 | Dove ci troviamo con la 231?
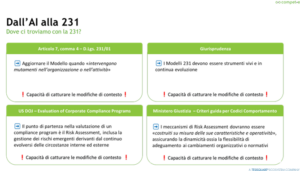
Dall’AI alla 231: fino a qui abbiamo parlato di AI e stato dell’arte (cosa quindi è già fattibile/disponibile per tutti).
Ma qual è lo stato dell’arte della 231? In particolare, a che punto siamo riguardo la specifica capacità dei Modelli di catturare le informazioni che provengono dal contesto interno ed esterno? E’ chiaro che ci stiamo riferendo alla componente del Risk Assessment (la famosa Mappa delle attività sensibili 231).
Anzitutto perché è così importante questa capacità di catturare le informazioni da contesto interno ed esterno per i programmi di conformità e in particolare per i Modelli 231?
Per capirlo utilizziamo questi 4 punti che battono tutti sullo stesso problema (e su cui l’AI ci può davvero aiutare come abbiamo visto nelle precedenti slides).
Non possiamo non partire dal Decreto 231/01, sempre da tutti o quasi tutti considerato scarnissimo di indicazioni su come un Modello debba essere redatto e gestito nel tempo, l’Articolo 7, comma 4 del Decreto 231 ci fornisce invece un’indicazione molto preziosa in tema di Efficace Attuazione del Modello richiedendo: «una verifica periodica e l’eventuale modifica dello stesso quando sono scoperte significative violazioni delle prescrizioni ovvero quando intervengono mutamenti nell’organizzazione o nell’attività» In altri termini, viene espressamente richiesta al compliance program, cioè al Modello 231 «la capacità di catturare le modifiche di contesto interno ed esterno»!
Veniamo al secondo punto, la Giurisprudenza in ambito 231 che abbiamo sintetizzato (consentitemi un pò di cherry picking) con questa asserzione che si trova ripetuta in importanti e numerose sentenze che in questi oltre 20 anni di vita del Decreto si sono succedute.
Quindi “No ai Modelli Statici” -> “Si ai Modelli Dinamici”. E’ chiaro che l’oggetto di questo rilievo riguarda l’efficace attuazione dei Modelli 231. Conferma cioè che i Modelli devono essere dinamici e costantemente aggiornati per essere efficaci nella prevenzione della responsabilità delle imprese. In altre parole conferma la nostra affermazione che i Modelli 231 devono avere la «capacità di catturare le modifiche di contesto interno ed esterno».
Andiamo al terzo punto “US DOJ’s evaluation of the compliance program guide” e cerchiamo ispirazione o una conferma nelle linee guida che il Ministero di Giustizia americano (US Department of Justice) redige ed aggiorna per i giudici che devono valutare la bontà di un corporate compliance program, cioè la sua adeguatezza ed efficacia. Gli addetti ai lavori 231 sanno che questo è sempre stato un documento di riferimento (in tutta onestà ne sentii parlare per la prima volta direttamente da un famoso Pubblico Ministero che tra i primi si stava specializzando – come PM intendo – in ambito 231).
Particolare attenzione è richiesta su come il Compliance Program sia in grado di rilevare (e gestire) i rischi emergenti derivanti dal continuo evolversi delle circostanze interne ed esterne che modificano il profilo di rischio iniziale.
Di nuovo stiamo parlando di «Capacità di catturare le modifiche di contesto interno ed esterno»
Arriviamo all’ultimo punto, anche in ordine di tempo, trattandosi dei criteri guida per la redazione di codici di comportamento in ambito 231 delle associazioni rappresentative degli enti, rilasciato nella sua ultima versione nel febbraio 2025.
Leggiamo «affinché possa dirsi idoneo a prevenire reati della specie di quello verificatosi, il modello organizzativo e i singoli protocolli di prevenzione adottati in concreto dovranno essere calati nella realtà aziendale in cui sono destinati a trovare attuazione; i meccanismi di risk assessment e risk management di ciascun ente dovranno essere, in altri termini, costruiti “su misura” delle sue caratteristiche e della sua operatività» e poi poco dopo «un ulteriore criterio di riferimento riguarda il connotato della dinamicità, da intendersi come capacità … di intercettare … [diremmo noi adattarsi (non rigido)] … alle evoluzioni dei fenomeni da considerare e gestire».
Anche quest’ultimo punto ci conferma il requisito per i Modelli o i Compliance Program di possedere la «Capacità di catturare le modifiche di contesto interno ed esterno»
La valutazione dei rischi-reato 231 | Metodologie di Risk Assessment
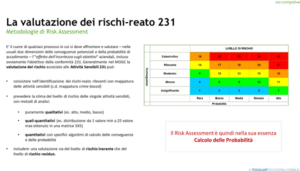
Arriviamo quindi al cuore del problema. Ossia alla componente dei Modelli 231 – così come di qualsiasi altro Compliance Program – che ne costituisce la base, le fondamenta: la mappa delle attività sensibili che tutti noi sappiamo essere il risultato di un Risk Assessment. Vi ho riportato le definizioni ISO (in questo caso 31000) perché hanno il pregio di farci focalizzare sul fatto che:
1) questa valutazione/stima deve essere fatta nelle due dimensioni delle conseguenze potenziali e della probabilità di accadimento
2) la valutazione ha ad oggetto la stima/valutazione appunto del «l’effetto dell’incertezza sugli obiettivi» [in assoluto la migliore definizione di rischio]
Nel caso della 231 è la valutazione che un’azienda compie per identificare le attività sensibili, rispetto ad un elenco di rischi-reato tra i propri processi di business o di supporto al business. Si tratta cioè di quelle attività a rischio 231 nell’ambito delle quali (es. vendite alla PA) o con il supporto delle quali (es. gestione delle risorse finanziarie) potrebbe essere commesso uno o più rischi-reato 231 nell’interesse o vantaggio dell’organizzazione determinando una responsabilità dell’ente ai sensi della 231 con le conseguenze che tutti voi conoscete.
Ora il D.Lgs 231 nulla ci dice sulla metodologia da impiegare per effettuare questo Risk Assessment, questa attività di identificazione e valutazione dei rischi relativi alle Attività Sensibili.
Possiamo quindi trovare nei Modelli approcci e metodologie molto diverse tra loro, che vi ho riepilogato qui di seguito:
Il primo è l’approccio più semplice e iniziale, secondo il quale ci si limita ad identificare i rischi-reato rilevanti/attinenti e quelli non rispetto all’organizzazione, andando a codificare delle attività sensibili (pura mappatura c.d. “crime based”).
Si trovano però sempre più nei Modelli delle valutazioni di rischio che includono la determinazione/stima anche di un livello di rischio. Questo livello di rischio può essere determinato con l’impiego di 3 tipologie di metodi di Risk Assessment:
- puramente qualitativi (Alto Medio Basso)
- quali-quantitativi (es. impiego di una distribuzione da 1 a 25 in cui collocare dei valori lungo le due dimensioni dell’impatto e della probabilità)
- quantitativi cioè con specifici algoritmi attraverso cui calcolare l’impatto, le probabilità e la loro combinazione
Infine, queste metodologie possono includere una valutazione sia del rischio lordo che del rischio netto.
Quello che trovate nella slide è un esempio di metodo quali-quantitativo di Risk Assessment attraverso l’impiego di una Risk Matrix anche chiamata Risk Heat Map per il caratteristico impiego dei colori.
Nonostante tutte queste sfumature e diversi approcci, possiamo comunque affermare e concordare che i Modelli 231 o i Compliance Programs in generale poggiano tutti su un’attività fondamentale che si chiama Risk Assessment che nella sua essenza è … CALCOLO DELLE PROBABILITA’.
Mi sembra che esisteva già qualcos’altro che avevamo definito nella sua essenza “Calcolo delle Probabilità”!
I limiti delle Matrici di Rischio | Lo standard nella valutazione dei rischi 231

Le Risk Heat Maps / Matrici di rischio a colori già da tempo sono messe in discussione e criticate da molti specialisti (specie in ambito RM) riguardo la loro (in)capacità di supportare adeguatamente le decisioni. Tra i critici più illuminati e illuminanti cito Horst Simon The Original Risk Culture Builder dalle cui pubblicazioni ho tratto evidente ispirazione in questa slide, insieme allo stesso Prof. Hernan Huwyler, MBA CPA e a Marco Nutini . Ricordiamoci che si tratta pur sempre di strumenti per supportare alla fine della fiera l’uomo/l’organizzazione di uomini quando sono chiamati a prendere una decisione su qualcosa che deve ancora avvenire (=futuro/incerto).
Vediamo questi limiti che possiamo per comodità riferire alla metodologia di RA oggi più usata anche in ambito 231: quella quali-quantitativa.
Cominciamo con i limiti che si dovrebbero conoscere (e quindi teoricamente accettare) ancora PRIMA di usare questa metodologia:
- pregiudizi intrinseci nei criteri/scale adottate (i.e. le soglie che fanno passare da medio ad alto sono soggettive)
- soggettività nelle valutazioni (il basso per me, non è uguale al basso per te)
- bassa risoluzione (es. 3X3 che giudica di medesima alta probabilità un evento stimato al 67% così come uno stimato al 99%) non consentendo di cogliere sfumature invece di rilevante significato
- rischi con impatto enormemente diverso valutati con il medesimo rating (un rischio con il 10% di probabilità e una perdita stimata di €10M può ricadere nella stessa categoria di un rischio con l’1% di probabilità e una perdita stimata di €100M)
- impossibile prioritarizzazione come conseguenza della soggettività e degli altri limiti sopra detti (es. nel definire le azioni di trattamento dovresti partire con quelli probabili al 99% ma la tua matrice considera quei rischi alti quanto quelli probabili al 67%).
- limiti nell’aggregazione delle esposizioni stimate e conseguente inefficiente allocazione delle risorse (il RM è anche al servizio di chi stima le coperture necessarie per …)
- per i puristi del RM, la moltiplicazione tra impatto e probabilità è sbagliata (come se stessi moltiplicando mele con pere) e comporta la sovrastima dell’esposizione di circa il 60%. La combinazione si realizza con la convoluzione di due distribuzioni (una di impatto che è continua e una di probabilità che è discreta)
Ma vediamo ora i limiti che si manifestano DURANTE un risk assessment condotto con l’impiego di una metodologia quali-quantitativa per la valutazione dei rischi:
- Danno una illusione di controllo, promettendo una veloce e semplice soluzione a problemi complessi senza imporre uno studio accurato o degli sforzi di calcolo complessi. Se teoricamente è meno complesso avere l’idea e stimare l’impatto, è davvero estremamente difficile calcolare la probabilità anche considerato che nel mondo reale i rischi generalmente non sono certamente legati ad un solo fattore. Eppure con una matrice impatto X probabilità la gran parte delle persone in poco tempo esprime una stima sia dell’impatto che della probabilità, spesso senza nemmeno compiere un vero minimo sforzo!
- Le matrici di rischio non richiedono competenze speciali in analisi dei dati e metodologie di analisi quantitativa dei rischi, quindi (tendenzialmente) troppe persone possono fare un RA. Mi ci metto dentro anche io…soprattutto se guardiamo oggi al profilo di un data scientist!
- La visualizzazione grafica tende a fornire una falsa sicurezza e a semplificare eccessivamente i rischi facendoli percepire come indipendenti gli uni dagli altri e soprattutto portando il lettore della matrice a non valutare le assunzioni e i criteri sottostanti.
- Gli esseri umani non hanno sviluppato una capacità di percepire rischi «non lineari»: i nostri istinti si sono evoluti in rapporto a danni potenziali diretti e immediati nel nostro ambiente circostante, quando invece il rischio è legato a molti fattori e può essere interdipendente con altri rischi (pensiamo al rischio di un attacco informatico!). Affidarsi all’istinto umano nella valutazione del rischio quantomeno non è una mossa di buon senso. Tra l’altro, parlando di valutazioni basate sull’istinto, gli esseri umani sono naturalmente avversi al rischio con connotazione negativa (=perdita) che tendono a sottostimare e più propensi/ben disposti al rischio con connotazione positiva (=guadagno) che tendono a sovrastimare
Vediamo ora i limiti che emergono DOPO aver svolto un risk assessment con metodologia quali-quantitativa:
- E’ un po’ paradossale il fatto che i risk register/matrici di rischio tendono a creare una visione che guarda più indietro che avanti, quando il Risk Management dovrebbe invece riguarda l’incerto ossia il futuro.
- Se ponete la domanda «come avete fatto a valutare di colore verde il rischio X» difficilmente la persona che ha partecipato alla valutazione è in grado di illustrare in maniera oggettiva e basandosi sui dati il calcolo o simil calcolo con cui si è giunti a quel risultato. La ripetibilità è quindi tutt’altro che raggiungibile.
- Spesso la facilità nel loro impiego porta ad omettere la raccolta, registrazione e condivisione delle preziosissime informazioni di contesto, avendo in molte matrici di rischio giusto qualche colore e aggettivo.
- E veniamo infine ad un problema molto pesante per qualsiasi compliance program e in particolare per i Modelli 231: le matrici di rischio sono al 100% statiche mancando totalmente o quasi di elementi che gli consentono di muoversi nel tempo. Sono una fotografia di un’azienda in un determinato momento quando noi tutti sappiamo che invece le cose cambiano velocemente e continuamente all’interno e all’esterno di un’azienda. Tra i fattori di rischio dovrebbe includersi anche il comportamento effettivo delle misure di trattamento nel modificare i rischi (efficacia dei controlli) che tutti noi sappiamo può cambiare velocemente e significativamente, modificando rilevantemente l’esposizione ai rischi. Per quanto tempo può essere considerata valida e rappresentativa (“up to date”) una matrice di rischio pur ben fatta a T0?
L’uso dell’AI nei Modelli 231 | AI can do it better – verso un nuovo gold standard nella valutazione dei rischi
Veniamo quindi al tema di questo webinar: come l’AI può supportare un Modello 231, anzitutto nella componente centrale (nonché base di qualsiasi Modello) rappresentata dalla valutazione dei rischi-reato.
Abbiamo proclamato che l’AI can do it better: la tecnologia c’è, è solida (addirittura è la vera essenza dell’AI) e supera tutti i limiti che abbiamo visto in precedenza, rendendo obsoleto qualsiasi modo di valutare i rischi diverso da una metodologia quantitativa. Essa è il nuovo gold standard per il RA con superamento contestuale degli ostacoli o difficoltà dei metodi quantitativi come ad esempio l’assenza di dati o l’incapacità di un algoritmo di cogliere adeguatamente alcune preziose informazioni di contesto.
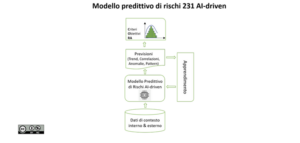
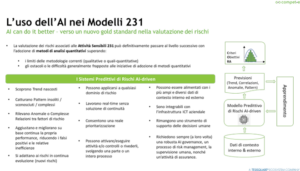
Ho cercato di schematizzare un sistema predittivo di rischi guidato dall’AI con questo grafico che vi vado ora ad illustrare prima di passare in rassegna tutti i suoi benefici e i vantaggi (un’altra slide piena, perdonatemi). Lo schema richiama in qualche modo alcuni grafici degli autori che ho citato precedentemente.
Non possiamo non partire dai dati: quelli di contesto interno & esterno che dovranno prima addestrare e poi alimentare a regime il sistema predittivo di rischi guidato dall’AI.
Al centro mettiamo direttamente il Modello (nel senso della terminologia propria dell’AI) e il suo schema caratteristico di apprendimento e miglioramento continuo. Il nostro Modello, grazie agli algoritmi di ML, sarà in grado di cogliere dal vasto set di dati che gli dovremo fornire, le informazioni di nostro interesse nella forma di PREVISIONI identificando trend, correlazioni, anomalie, pattern.
Le previsioni del sistema predittivo di rischi guidato dall’AI daranno vita/dinamicità al RA, ai suoi criteri e assunzioni e agli stessi obiettivi il conseguimento dei quali è appunto incerto per effetto dei rischi.
Vediamo come in concreto possono questi sistemi predittivi di rischi guidati dall’AI possono aiutarci:
- Scoprono Trend nascosti
- Catturano Pattern insoliti / sconosciuti / complessi
- Rilevano anomalie o complesse relazioni tra fattori di rischio …. stiamo parlando dei benefici chiave dell’AI che i tradizionali metodi quantitativi non erano certamente in grado di assicurare a questi livelli
- Aggiustano e migliorano su base continua la propria performance, riducendo i falsi positivi e le relative inefficienze (ad es. avete ben presente il costo di gestione dei falsi positivi, in un sistema o procedura AML?)
- Possono applicarsi a qualsiasi dominio di rischio (non solo compliance quindi)
- Lavorano real-time e senza mai fermarsi
- Consentono una reale prioritarizzazione, e quando si deve decidere come allocare le risorse nei trattamenti ciò è alquanto importante
- Possono attivare o eseguire attività, controlli o rivederli, svolgendo una parte o un intero processo. Penso che voi tutti sentiate sempre più parlare di Agentic AI con gradi di autonomia sempre più ampi (rispetto all’intervento/interazione con l’essere umano)
- Posso essere alimentati con quantità praticamente infinite di dati di contesto esterno e interno, quando potete immaginare la nostra difficoltà ad aggiornare manualmente una formula di calcolo o anche solo un report per aggiungere un solo parametro
- Sono pienamente integrabili con l’infrastruttura ICT aziendale interna ed esterna
- Rimangono uno strumento di supporto per le decisioni umane (anche quelle ultime o di più alto livello, come nel nostro caso un OdV o ancora di più in CdA)
- A loro volta richiedono una robusta AI Governance, AI RM e ovviamente la continua supervisione umana (i sistemi di AI possono anche degradare, cioè la loro performance può dirigersi in una direzione diversa da quella programmata e attesa), nonché l’internal audit! E qui si potrebbe entrare nel tema dei rischi (certamente non irrilevanti) derivanti dall’impiego dell’AI in un’organizzazione. Ambito di estremo interesse (insieme ad una robusta preliminare valutazione del ROI – ritorno sull’investimento) sui cui personalmente sto io stesso facendo le prime esperienze e che temo (“gut instinct”) molte aziende stiano trascurando dalla fretta di implementare l’AI!
… e se continuo ad usare i vecchi metodi | Un dialogo immaginario

Vediamo se c’è tempo per leggere tutto questo dialogo immaginario, ispirato da uno simile elaborato dal Prof. Hernan Huwyler, MBA CPA che lo immaginava in un’aula di giustizia a stelle e strisce e ovviamente non riferito alla 231.
Altrimenti lo possiamo saltare. E’ una pura finzione, non me ne vogliano i Compliance Officer e ha il solo scopo di far emergere – grazie alla tecnica platonica del Dialogo – i limiti delle metodologie qualitative o quali-quantitative e delle matrici di rischio o mappe a colori che abbiamo discusso ampiamente.
Quello che invece deve essere messo agli atti è la conclusione, ossia che l’AI ha posto fine all’era del «non potevo sapere» (cit. Marco Nutini)!
Pone cioè fine all’era delle valutazioni qualitative, a sentimento, non basate sui dati/numeri, e sulle informazioni in essi contenuti: questo vale ovviamente per il Risk Management, per la Compliance, per l’Internal Audit e per la Governance nel suo complesso.
Conclusioni
L’integrazione dell’Artificial Intelligence anche nei processi di valutazione dei rischi-reato rappresenta una frontiera straordinaria per la Compliance Aziendale. L’AI non sostituisce il giudizio umano, ma lo potenzia, lo supporta e lo rende incredibilmente più efficace e nel complesso decisamente più efficiente. In un ambito come quello dei Modelli ex D.Lgs. 231/2001, dove la prevenzione dei rischi-reato rimane l’obiettivo principale, l’adozione di strumenti intelligenti è sempre più indifferibile e di fatto un must have: tutte le altre metodologie di Risk Assessment diverranno, infatti, sempre più agli occhi di tutti (e probabilmente presto anche dell’AG) obsolete e conseguentemente il risultato di una malpractice.
Ti invito a riflettere su come l’AI possa essere integrata nel vostro Modello 231 e, se vuoi approfondire, sono ovviamente a disposizione per un confronto diretto.



